View this post on Medium.com
How To Read the HTML Specification
A Guide For Web Developers
What is the HTML Specification
The HTML Specification is a document written by the w3c that defines all of the rules of HTML, or Hypertext Markup Language.
Many web developers do not know how or when to refer to the HTML “Spec”, and how it can help them to become better web developers. In this article I want to share some background on “the spec”, and then share my tips on how to make the best use of it.

What is the HTML Specification
As mentioned before, the Spec defines everything that should be accepted and read by web browsers and other user agents.
It defines, for example, all of the metadata that should be allowed in any HTML document on the internet, for example page titles. It also defines every HTML “Tag” that can be used in the body of those webpages. It is because of this specification, for example, that <dog> does not exist as a meaningful element, while <p> does.
It is important to note that the specification doesn’t dictate what web browsers will accept, but rather each browser is in a constant state of trying to ‘conform’ or catch up to the HTML specification, which changes infrequently but consistently.
The HTML spec is focused around the definition of valid, or “conforming” HTML documents, their categories and attributes.
Why Should You Use The Spec
Because this spec is so incredibly influential, it is a good idea to spend some time reading it. At the very least it is a good idea to know how to read it, so that you can look to the documentation the next time you are in need of an answer. You might think “yea but whenever I google something I get a result from MDN, why should I learn another doc?”, and while that is true, it is always better to know how to go to the source when you need to.
Learning to use the Spec
The HTML specification is one of the most important and leas understood pieces of documentation involved in web development. The document has been modified recently with a new look and feel, but the contents are still as mercurial as ever. I’ll explain a few of the main concepts involved in reading the spec below, to hopefully give you a better understanding of what to look for when you endeavor to read it yourself.
Terms
Terms are very important in the doc. Here are some of the most important ones:
- Elements: The most basic way to define a meaningful group of content inside your document. For example:
<p></p> - Categories: The spec defines categories of elements, for example “sectioning content” and “metadata content” and these categories are very important in terms of the interactions between elements
- Content Model: The content model is the list of different categories of content that can be nested inside of a given element. For example, the
<p>tag can have other "phrasing" content inside of it, but not "sectioning content" - Conforming: This means that the text is “valid” in the current specification. You can confirm that your HTML document is conforming using the following website.

How to read the Spec
First things first — Google Your Shit.
If you are working through your document and think that you might be able to replace a tag with a more specific one, just google to make sure. The following search:
“html element for making up dates”
Will lead you to a depth of knowledge on the topic, likely in the HTML spec itself or in secondary sources like MDN.
Understand the Element Categories
Become familiar with the types of HTML elements that are available to you. Then when you begin to mark up your document you will know where to look in the specification for the type of tag you need.
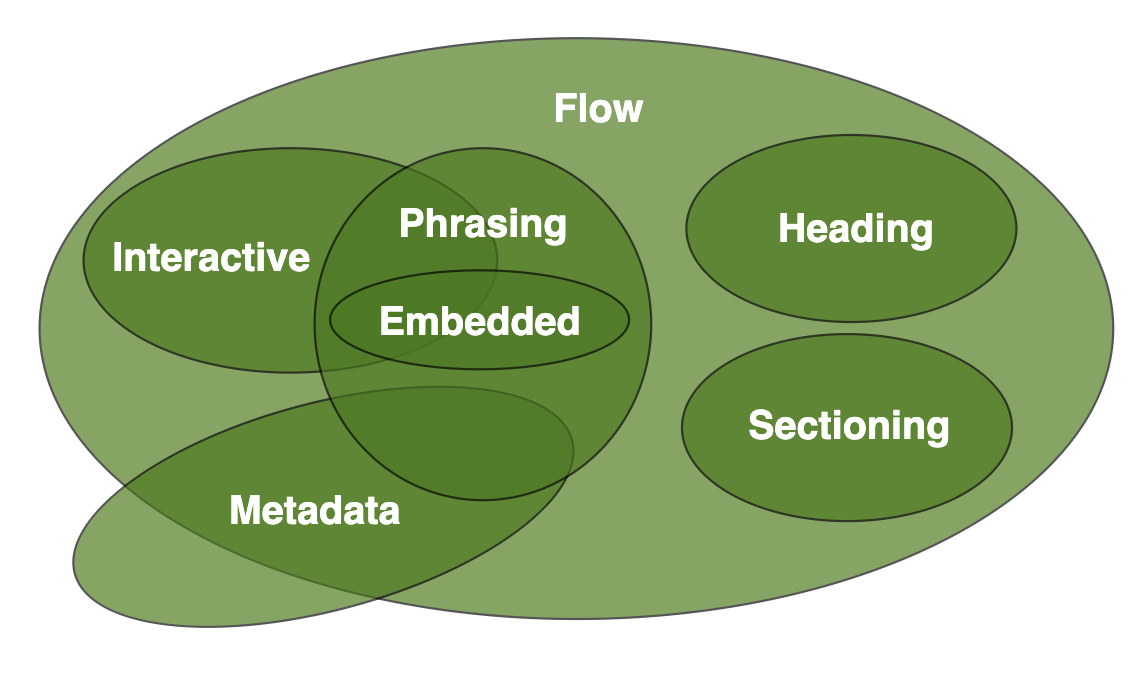 For example, when you need to look up anything related to the high level document organization you will know to look in the “sectioning content” category for more information.
For example, when you need to look up anything related to the high level document organization you will know to look in the “sectioning content” category for more information.
The section that I spend the most time in is this one, which defines the majority of the elements used in the document body, as well as their attributes and content models.
Find your Element and get familiar with purpose, content model, and attributes
Once I’m in the document, I usually just search for the element that I think I’ll be working with, via a ctrl+f find, and then navigate to that section of the spec.
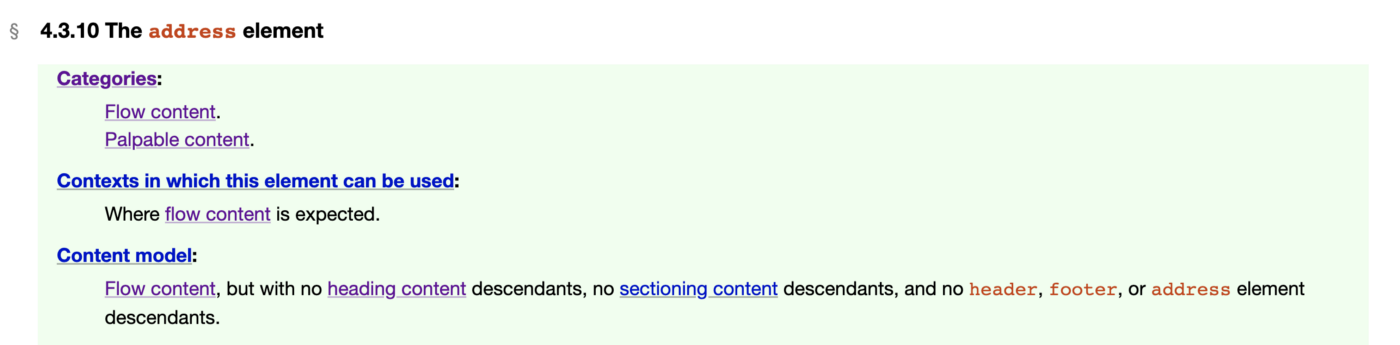

After that I take some time to read about the elements intended purpose (because often this is actually very different from how it is used on the web) and then its content model and any attributes that it might have that could be useful. For more interactive elements that have many complex attributes, like the <audio> element, I will usually go to MDN for more information because their structure is easier to understand.